Kubernetes Architecture
Introduction
In this chapter, we will explore the Kubernetes architecture, the components of a control plane node, the role of the worker nodes, the cluster state management with etcd and the network setup requirements. We will also learn about the Container Network Interface (CNI), as Kubernetes' network specification.
Kubernetes Architecture
- At a very high level, Kubernetes is a cluster of compute systems categorized by their distinct roles:
- One or more control plane nodes
- One or more worker nodes (optional, but recommended).
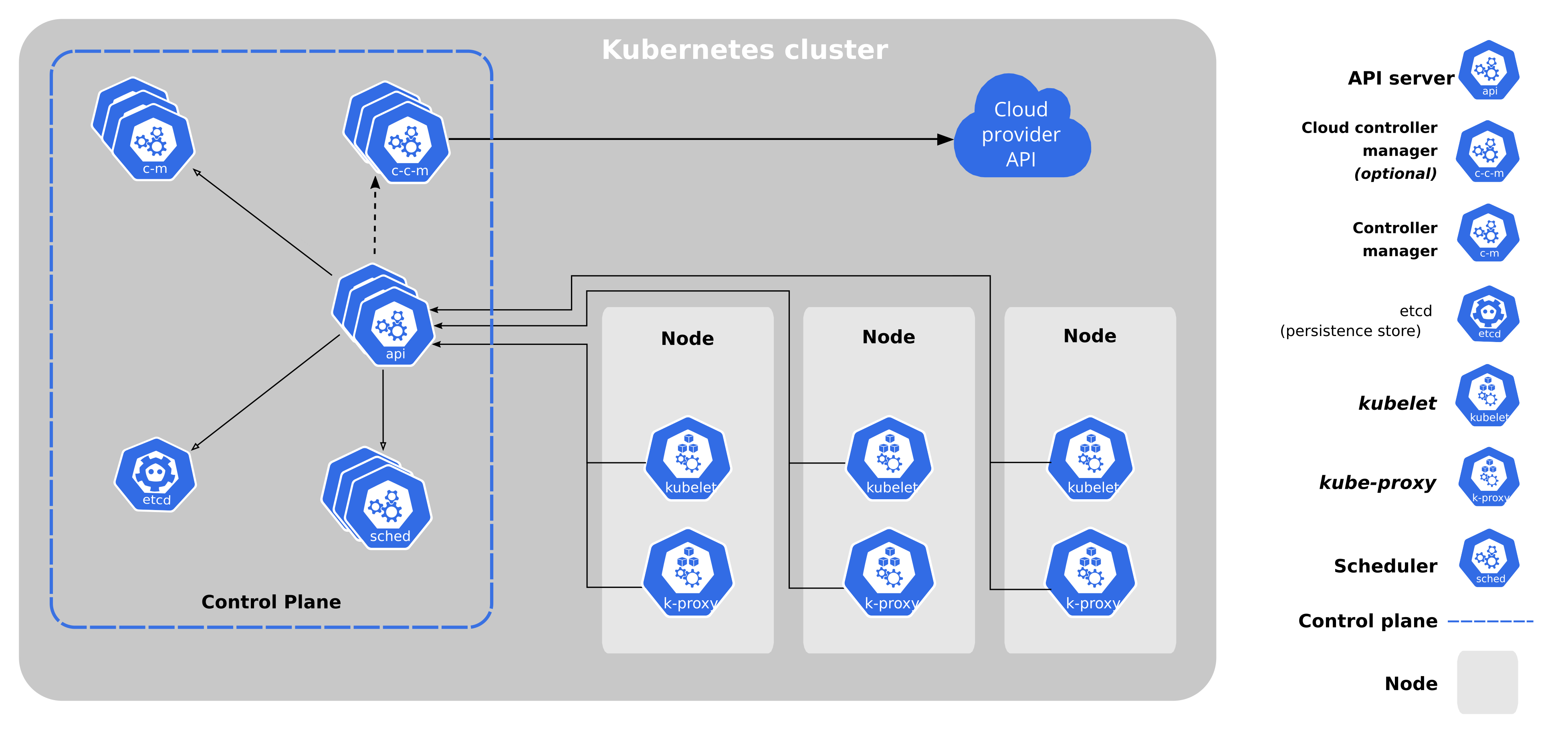
Control Plane Node Overview
- The control plane node provides a running environment for the control plane agents responsible for managing the state of a Kubernetes cluster, and it is the brain behind all operations inside the cluster.
- The control plane components are agents with very distinct roles in the cluster’s management.
- In order to communicate with the Kubernetes cluster, users send requests to the control plane via a Command Line Interface (CLI) tool, a Web User-Interface (Web UI) Dashboard, or an Application Programming Interface (API).
- It is important to keep the control plane running at all costs. Losing the control plane may introduce downtime, causing service disruption to clients, with possible loss of business.
- To ensure the control plane’s fault tolerance, control plane node replicas can be added to the cluster, configured in High-Availability (HA) mode. While only one of the control plane nodes is dedicated to actively manage the cluster, the control plane components stay in sync across the control plane node replicas.
- This type of configuration adds resiliency to the cluster’s control plane, should the active control plane node fail.
- To persist the Kubernetes cluster’s state, all cluster configuration data is saved to a distributed key-value store which only holds cluster state related data, no client workload generated data.
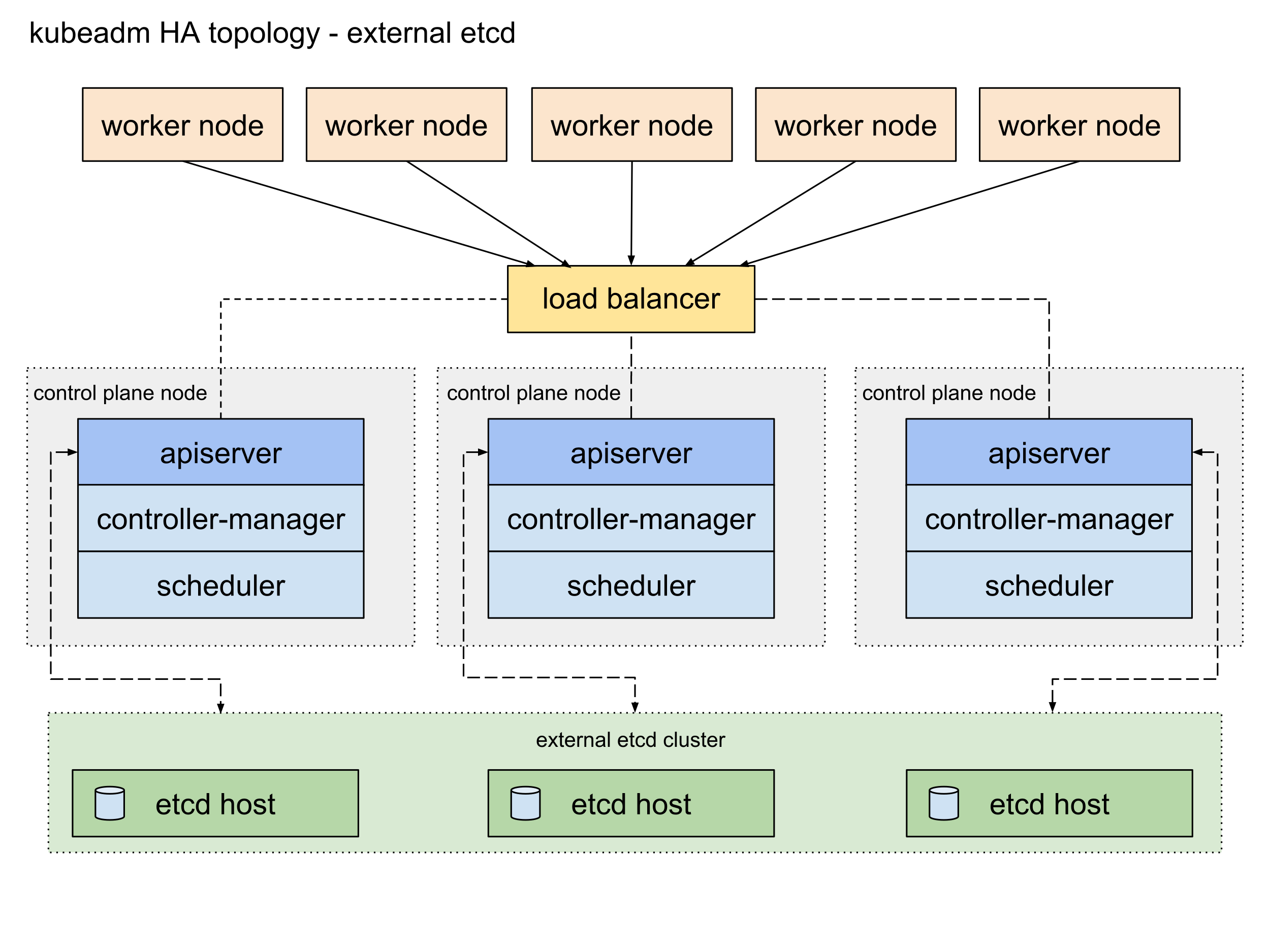
- The key-value store may be configured on the control plane node (stacked topology), or on its dedicated host (external topology) to help reduce the chances of data store loss by decoupling it from the other control plane agents.
- In the stacked key-value store topology, HA control plane node replicas ensure the key-value store’s resiliency as well.
- However, that is not the case with external key-value store topology, where the dedicated key-value store hosts have to be separately replicated for HA, a configuration that introduces the need for additional hardware, hence additional operational costs.
Control Plane Node Components
A control plane node runs the following essential control plane components and agents:
- API Server
- Scheduler
- Controller Managers
- Key-Value Data Store.
In addition, the control plane node runs:
- Container Runtime
- Node Agent
- Proxy
- Optional addons for cluster-level monitoring and logging.
Control Plane Node Components: API Server
- All the administrative tasks are coordinated by the kube-apiserver, a central control plane component running on the control plane node.
- The API Server intercepts RESTful calls from users, administrators, developers, operators and external agents, then validates and processes them.
- During processing the API Server reads the Kubernetes cluster’s current state from the key-value store, and after a call’s execution, the resulting state of the Kubernetes cluster is saved in the key-value store for persistence.
- The API Server is the only control plane component to talk to the key-value store, both to read from and to save Kubernetes cluster state information - acting as a middle interface for any other control plane agent inquiring about the cluster’s state.
- The API Server is highly configurable and customizable. It can scale horizontally, but it also supports the addition of custom secondary API Servers, a configuration that transforms the primary API Server into a proxy to all secondary, custom API Servers, routing all incoming RESTful calls to them based on custom defined rules.
Control Plane Node Components: Scheduler
- The role of the kube-scheduler is to assign new workload objects, such as pods encapsulating containers, to nodes - typically worker nodes.
- During the scheduling process, decisions are made based on current Kubernetes cluster state and new workload object’s requirements.
- The scheduler obtains from the key-value store, via the API Server, resource usage data for each worker node in the cluster.
- The scheduler also receives from the API Server the new workload object’s requirements which are part of its configuration data.
- Requirements may include constraints that users and operators set, such as scheduling work on a node labeled with disk==ssd key-value pair.
- The scheduler also takes into account Quality of Service (QoS) requirements, data locality, affinity, anti-affinity, taints, toleration, cluster topology, etc.
- Once all the cluster data is available, the scheduling algorithm filters the nodes with predicates to isolate the possible node candidates which then are scored with priorities in order to select the one node that satisfies all the requirements for hosting the new workload.
- The outcome of the decision process is communicated back to the API Server, which then delegates the workload deployment with other control plane agents.
- The scheduler is highly configurable and customizable through scheduling policies, plugins, and profiles. Additional custom schedulers are also supported, then the object’s configuration data should include the name of the custom scheduler expected to make the scheduling decision for that particular object; if no such data is included, the default scheduler is selected instead.
- A scheduler is extremely important and complex in a multi-node Kubernetes cluster, while in a single-node Kubernetes cluster possibly used for learning and development purposes, the scheduler’s job is quite simple.
Control Plane Node Components: Controller Managers
- The controller managers are components of the control plane node running controllers or operator processes to regulate the state of the Kubernetes cluster. Controllers are watch-loop processes continuously running and comparing the cluster’s desired state (provided by objects' configuration data) with its current state (obtained from the key-value store via the API Server). In case of a mismatch corrective action is taken in the cluster until its current state matches the desired state.
- The kube-controller-manager runs controllers or operators responsible to act when nodes become unavailable, to ensure container pod counts are as expected, to create endpoints, service accounts, and API access tokens.
- The cloud-controller-manager runs controllers or operators responsible to interact with the underlying infrastructure of a cloud provider when nodes become unavailable, to manage storage volumes when provided by a cloud service, and to manage load balancing and routing.
Control Plane Node Components: Key-Value Data Store
- etcd is an open source project under the Cloud Native Computing Foundation (CNCF). etcd is a strongly consistent, distributed key-value data store used to persist a Kubernetes cluster’s state. New data is written to the data store only by appending to it, data is never replaced in the data store. Obsolete data is compacted (or shredded) periodically to minimize the size of the data store.
- Out of all the control plane components, only the API Server is able to communicate with the etcd data store.
- etcd’s CLI management tool - etcdctl, provides snapshot save and restore capabilities which come in handy especially for a single etcd instance Kubernetes cluster - common in Development and learning environments. However, in Stage and Production environments, it is extremely important to replicate the data stores in HA mode, for cluster configuration data resiliency.
- Some Kubernetes cluster bootstrapping tools, such as kubeadm, by default, provision stacked etcd control plane nodes, where the data store runs alongside and shares resources with the other control plane components on the same control plane node.
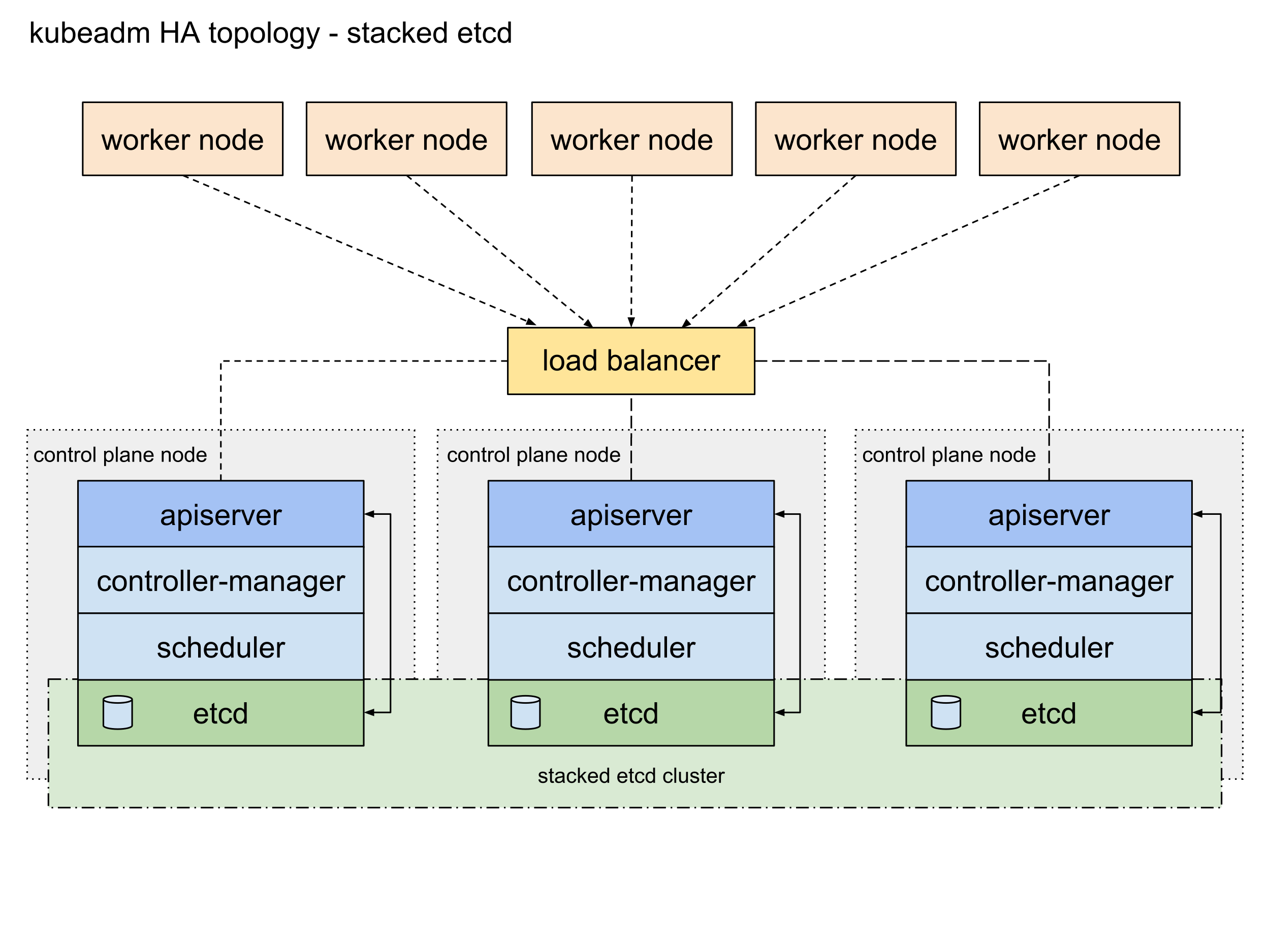
- For data store isolation from the control plane components, the bootstrapping process can be configured for an external etcd topology, where the data store is provisioned on a dedicated separate host, thus reducing the chances of an etcd failure.
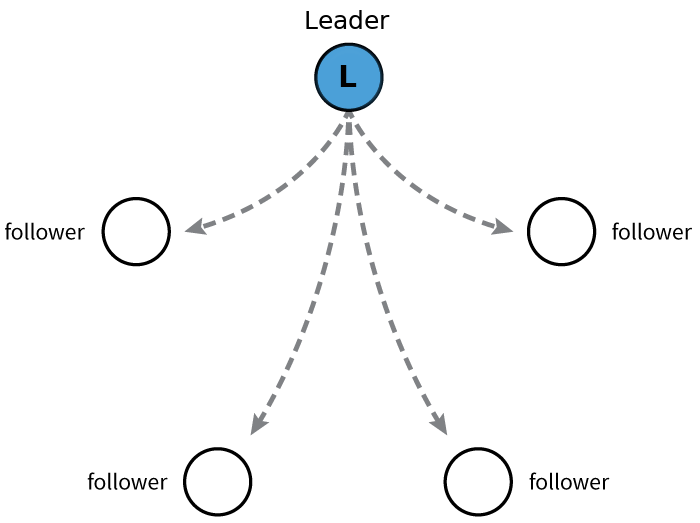
- Both stacked and external etcd topologies support HA configurations. etcd is based on the Raft Consensus Algorithm which allows a collection of machines to work as a coherent group that can survive the failures of some of its members. At any given time, one of the nodes in the group will be the leader, and the rest of them will be the followers. etcd gracefully handles leader elections and can tolerate node failure, including leader node failures. Any node can be treated as a leader.
- etcd is written in the Go programming language. In Kubernetes, besides storing the cluster state, etcd is also used to store configuration details such as subnets, ConfigMaps, Secrets, etc.
Worker Node Overview
- A worker node provides a running environment for client applications.
- Though containerized microservices, these applications are encapsulated in Pods, controlled by the cluster control plane agents running on the control plane node.
- Pods are scheduled on worker nodes, where they find required compute, memory and storage resources to run, and networking to talk to each other and the outside world.
- A Pod is the smallest scheduling work unit in Kubernetes.
- It is a logical collection of one or more containers scheduled together, and the collection can be started, stopped, or rescheduled as a single unit of work.
- Also, in a multi-worker Kubernetes cluster, the network traffic between client users and the containerized applications deployed in Pods is handled directly by the worker nodes, and is not routed through the control plane node.
Worker Node Components
A worker node has the following components:
- Container Runtime
- Node Agent - kubelet
- Proxy - kube-proxy
- Addons for DNS, Dashboard user interface, cluster-level monitoring and logging.
Worker Node Components: Container Runtime
Although Kubernetes is described as a “container orchestration engine”, it lacks the capability to directly handle and run containers. In order to manage a container’s lifecycle, Kubernetes requires a container runtime on the node where a Pod and its containers are to be scheduled. Runtimes are required on all nodes of a Kubernetes cluster, both control plane and worker. Kubernetes supports several container runtimes:
- CRI-O - A lightweight container runtime for Kubernetes, supporting quay.io and Docker Hub image registries.
- containerd - A simple, robust, and portable container runtime.
- Docker - A popular and complex container platform which uses containerd as a container runtime.
- Mirantis Container Runtime - Formerly known as the Docker Enterprise Edition.
Worker Node Components: Node Agent - kubelet
- The kubelet is an agent running on each node, control plane and workers, and communicates with the control plane. It receives Pod definitions, primarily from the API Server, and interacts with the container runtime on the node to run containers associated with the Pod. It also monitors the health and resources of Pods running containers.
- The kubelet connects to container runtimes through a plugin based interface - the Container Runtime Interface (CRI). The CRI consists of protocol buffers, gRPC API, libraries, and additional specifications and tools that are currently under development. In order to connect to interchangeable container runtimes, kubelet uses a shim application which provides a clear abstraction layer between kubelet and the container runtime.
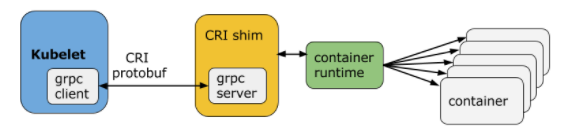
- As shown above, the kubelet acting as grpc client connects to the CRI shim acting as grpc server to perform container and image operations. The CRI implements two services: ImageService and RuntimeService. The ImageService is responsible for all the image-related operations, while the RuntimeService is responsible for all the Pod and container-related operations.
- Container runtimes used to be hard-coded into kubelet, but since the CRI was introduced, Kubernetes has become more flexible to use different container runtimes without the need to recompile. Any container runtime that implements the CRI can be used by Kubernetes to manage Pods, containers, and container images.
Worker Node Components: kubelet - CRI shims
- Shims are Container Runtime Interface (CRI) implementations, interfaces or adapters, specific to each container runtime supported by Kubernetes. Below we present some examples of CRI shims:
- cri-containerd - cri-containerd allows containers to be directly created and managed with containerd at kubelet’s request:

- CRI-O - CRI-O enables the use of any Open Container Initiative (OCI) compatible runtime with Kubernetes, such as runC:
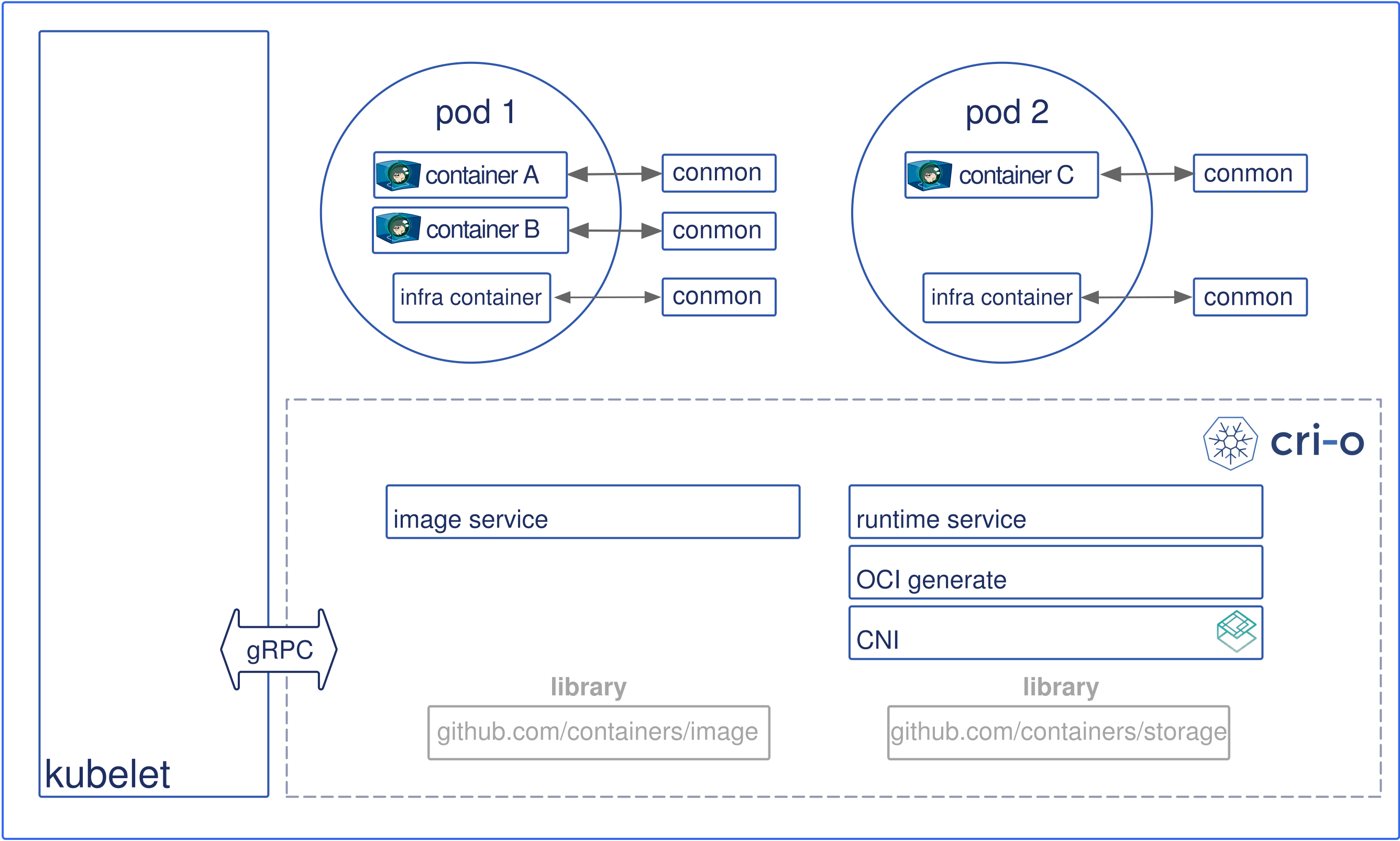
- dockershim and cri-dockerd - dockershim allows containers to be created and managed invoking Docker and its internal runtime containerd. Due to Docker’s popularity, this shim has been the default interface used by kubelet since Kubernetes was created. However, starting with Kubernetes release v1.24, the dockershim is no longer being maintained by the Kubernetes project, thus will no longer be supported by the kubelet node agent of Kubernetes. As a result, Docker, Inc. and Mirantis have agreed to introduce and maintain a replacement adapter, cri-dockerd that would ensure that the Docker Engine will continue to be a runtime option for Kubernetes, in addition to the Mirantis Container Runtime:

Worker Node Components: Proxy - kube-proxy
- The kube-proxy is the network agent which runs on each node, control plane and workers, responsible for dynamic updates and maintenance of all networking rules on the node. It abstracts the details of Pods networking and forwards connection requests to the containers in the Pods.
- The kube-proxy is responsible for TCP, UDP, and SCTP stream forwarding or random forwarding across a set of Pod backends of an application, and it implements forwarding rules defined by users through Service API objects.
Worker Node Components: Addons
Addons are cluster features and functionality not yet available in Kubernetes, therefore implemented through 3rd-party pods and services.
- DNS - Cluster DNS is a DNS server required to assign DNS records to Kubernetes objects and resources.
- Dashboard - A general purposed web-based user interface for cluster management.
- Monitoring - Collects cluster-level container metrics and saves them to a central data store.
- Logging - Collects cluster-level container logs and saves them to a central log store for analysis.
Networking Challenges
Decoupled microservices based applications rely heavily on networking in order to mimic the tight-coupling once available in the monolithic era.
Networking, in general, is not the easiest to understand and implement. Kubernetes is no exception - as a containerized microservices orchestrator it needs to address a few distinct networking challenges:
- Container-to-container communication inside Pods
- Pod-to-Pod communication on the same node and across cluster nodes
- Pod-to-Service communication within the same namespace and across cluster namespaces
- External-to-Service communication for clients to access applications in a cluster.
All these networking challenges must be addressed before deploying a Kubernetes cluster.
Container-to-Container Communication Inside Pods
- Making use of the underlying host operating system’s kernel virtualization features, a container runtime creates an isolated network space for each container it starts. On Linux, this isolated network space is referred to as a network namespace. A network namespace can be shared across containers, or with the host operating system.
- When a grouping of containers defined by a Pod is started, a special Pause container is initialized by the Container Runtime for the sole purpose to create a network namespace for the Pod. All additional containers, created through user requests, running inside the Pod will share the Pause container’s network namespace so that they can all talk to each other via localhost.
Pod-to-Pod Communication Across Nodes
- In a Kubernetes cluster Pods, groups of containers, are scheduled on nodes in a nearly unpredictable fashion.
- Regardless of their host node, Pods are expected to be able to communicate with all other Pods in the cluster, all this without the implementation of Network Address Translation (NAT). This is a fundamental requirement of any networking implementation in Kubernetes.
- The Kubernetes network model aims to reduce complexity, and it treats Pods as VMs on a network, where each VM is equipped with a network interface - thus each Pod receiving a unique IP address.
- This model is called “IP-per-Pod” and ensures Pod-to-Pod communication, just as VMs are able to communicate with each other on the same network.
- Let’s not forget about containers though. They share the Pod’s network namespace and must coordinate ports assignment inside the Pod just as applications would on a VM, all while being able to communicate with each other on localhost - inside the Pod.
- However, containers are integrated with the overall Kubernetes networking model through the use of the Container Network Interface (CNI) supported by CNI plugins.
- CNI is a set of a specification and libraries which allow plugins to configure the networking for containers. While there are a few core plugins, most CNI plugins are 3rd-party Software Defined Networking (SDN) solutions implementing the Kubernetes networking model.
- In addition to addressing the fundamental requirement of the networking model, some networking solutions offer support for Network Policies. Flannel, Weave, Calico are only a few of the SDN solutions available for Kubernetes clusters.
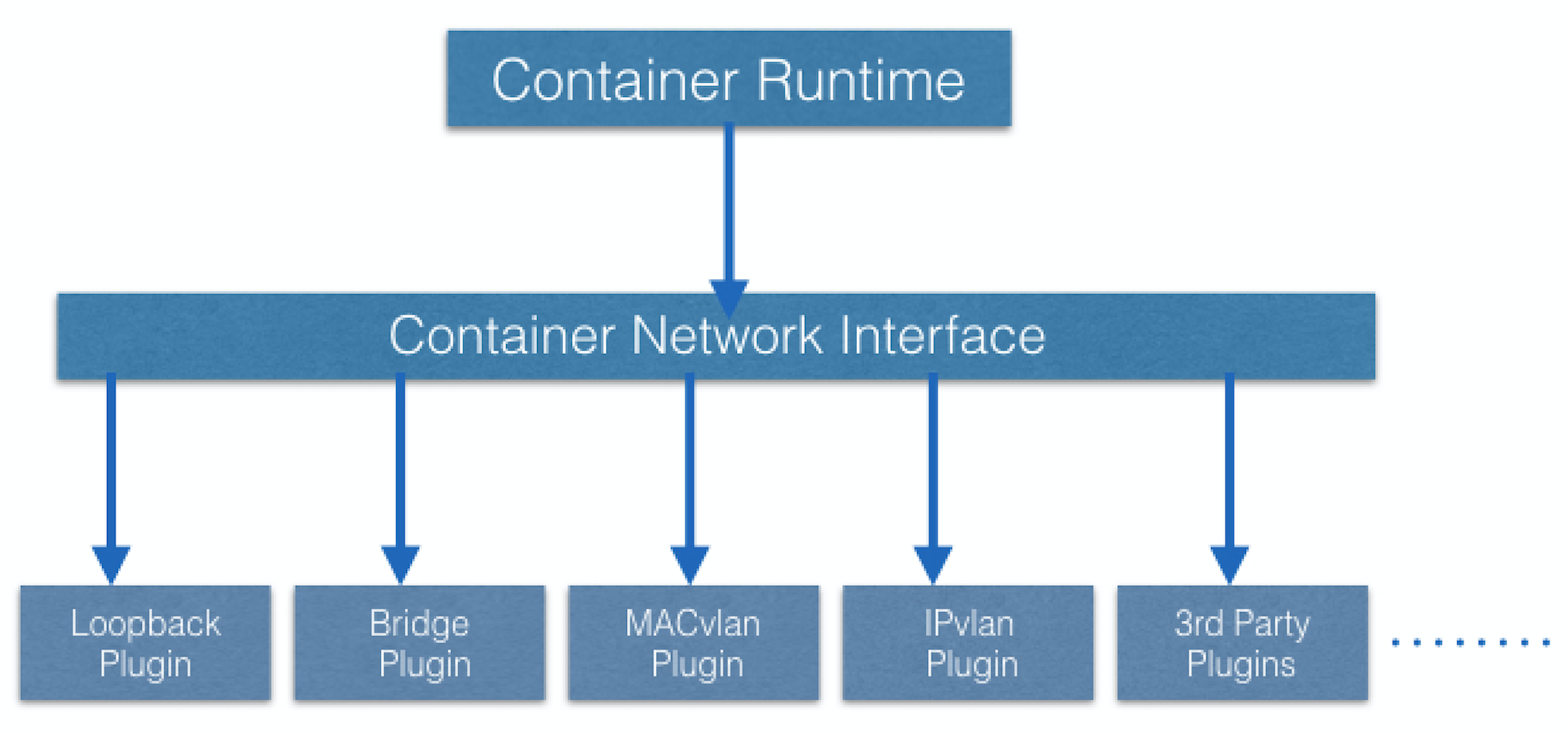
- The container runtime offloads the IP assignment to CNI, which connects to the underlying configured plugin, such as Bridge or MACvlan, to get the IP address. Once the IP address is given by the respective plugin, CNI forwards it back to the requested container runtime.
- For more details, you can explore the Kubernetes documentation.
Pod-to-External World Communication
- A successfully deployed containerized application running in Pods inside a Kubernetes cluster may require accessibility from the outside world.
- Kubernetes enables external accessibility through Services, complex encapsulations of network routing rule definitions stored in iptables on cluster nodes and implemented by kube-proxy agents.
- By exposing services to the external world with the aid of kube-proxy, applications become accessible from outside the cluster over a virtual IP address and a dedicated port number.
Learning Objectives (Review)
By the end of this chapter, you should be able to:
- Discuss the Kubernetes architecture.
- Explain the different components of the control plane and worker nodes.
- Discuss cluster state management with etcd.
- Review the Kubernetes network setup requirements.